
One of the benefits of generating a site as a static artefact (here using Jekyll but there are a gazillion tools) is that the finished product is a known quantity. Anything that's a known quantity can be tested!
A previous post in this series looked at testing the generated HTML for technical correctness… Things like if the HTML is well-formed or that links go to real destinations.
This post describes testing the meaning of the text in the generated HTML. Checking spelling, and keeping myself honest in my attempt to use more inclusive language.
Test the markdown itself
Since the HTML is generated from markdown. Is that markdown valid?
node_modules/.bin/remark . --use lint --frail
Remark is a tool that allows the use of more than one plugin for processing markdown.
Here the --use lint adds the linting plugin. --frail set it to exit with a non-zero code on warnings as well as errors.
This doesn't help test the meaning. But, it does help ensure that other errors that are found are located in the meaning and not in a typo. There are still old posts I grabbed from Blogger that are very messy HTML. Periodically I'll switch one to MarkDown and this helps catch errors fast.
Even better - test the spelling in the markdown
After yet another occasion where I proofread a post, published it, read it, and immediately saw a spelling mistake. It was time to automate the solution.
node_modules/.bin/mdspell _posts/**.md \
--en-gb \
--ignore-numbers \
--ignore-acronyms \
--report
MarkDown spellcheck is a tool for doing exactly that.
Here it
- grabs all the
.mdfiles - sets the dictionary to
--en-gb - ignores numbers and acronyms
- and is set to run in
reportmode
The tool has a report mode which outputs spelling errors and then exits with a non-zero code. And an interactive mode that pauses on each potential mistake allowing you to choose to ignore, add to a dictionary, or to correct.
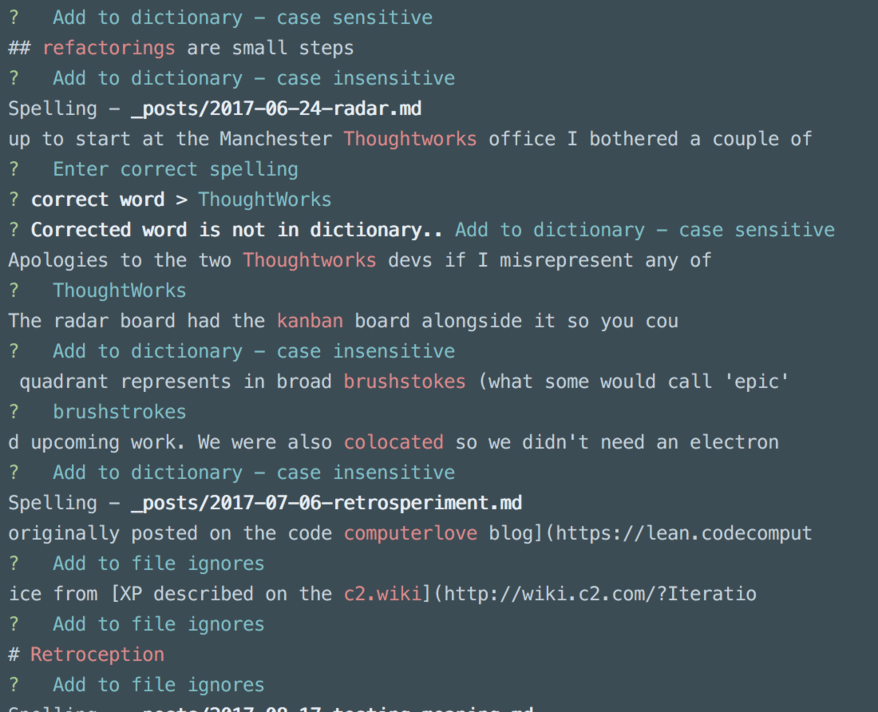
The interactive spelling mode can be pretty slow at checking the dictionary. There is an open issue about this.
As you train this tool, it populates a .spelling file so that you don't have to keep teaching it the domain-specific language you use. Mine's already hundreds of lines long.
Testing for inconsiderate language…
Alex is a tool for catching inconsiderate or insensitive language.
There is very little cost to modifying your language (replacing "guys" with "everyone" or "his" with "their"). And compared to the cost of excluding even one person, I consider it a worthwhile thing to try to improve.
Alex is run using this command: npx alex _posts --why
_poststells alex which directory to start in--whytries to output a source for the warning
he-she rule
_posts/2014-06-01-promises-part-2.md
197:160-197:162 warning `he` may be insensitive, use `they`, `it` instead he-she retext-equality
In that text I am referring to a man. So, I could ignore the warning. By adding an HTML comment to the markDown <!--alex ignore he-she-->. In each case replacing he-she with the reported rule in the output.
Or spend the (literal) second to convert that reference to they.
A file with more errors
_posts/2010-05-08-theres-more-in-them-that-hills.md
17:123-17:130 warning Don’t use “bitchin”, it’s profane bitchin retext-profanities
17:153-17:160 warning Don’t use “bitchin”, it’s profane bitchin retext-profanities
19:229-19:235 warning Be careful with “failed”, it’s profane in some cases failed retext-profanities
25:4-25:7 warning Reconsider using “God”, it may be profane god retext-profanities
31:360-31:365 warning `idiot` may be insensitive, use `foolish`, `ludicrous`, `silly` instead
Source: http://www.autistichoya.com/p/ableist-words-and-terms-to-avoid.html
Here's another example of the importance of context but also the unthinking use of language.
I wrote that post in 2010. I don't use that voice any more. But, I'm ok with bitchin' in the context it was used in. But it isn't about what I'm ok with. I don't know the reader and can rephrase without it.
Next failed is profane in some cases… in this post it's talking about software failing to send emails. I think it's ok. But I can also see how to rephrase the sentence. This is about trying to include as many people as possible. It takes seconds to rephrase the sentence.
Then a warning about "Oh God it's awful" - and there I'm talking about software I wrote :/ If you've worked with me, you may recognise the feeling :p
I feel relatively strongly that blasphemy is allowed. We should have freedom from religion as well as freedom of religion. I also feel strongly that I don't go out of my way to blaspheme.
So I might choose to set Alex not to warn me about the word 'god'
I can set my .alexrc file to contain
{
"allow": [
"god"
]
}
Or to rephrase the sentence. There's always another way to make yourself clear.
I use words like Idiot less and less since it takes little effort to replace them. On reading the paragraph it was in so many years after writing it doesn't add anything to the post at all. So I remove the entire paragraph.
And so…
These are small changes that help make writing more accessible. I am an imperfect human and find great value in automation that helps me avoid mistakes.
Update 2021: This has been in my drafts for four years. I am going to publish it with minimal editing in the interest of progress over perfection