
Part One - describing event-driven and serverless systems
Part Two - Infrastructure as code walking skeleton
Part Three - SAM Local and the first event producer
Part Four - Making streams of events
OK, four months since part four. I got a puppy and have written the code for this part of the series in 2 minute blocks after sleepless nights. Not a productive way to do things!
Getting ready to make some HTML
Now that the API lets clients propose destinations to the visit plannr the home page for the service can be built. It's going to show the most recently updated destinations.
In a CRUD SQL system the application would have been maintaining the most up-to-date state of each destination in SQL and you'd read them when the HTML is requested. But this application isn't storing the state of the destinations but the facts that it has been told about the destinations.
As an aside a lot of people don't realise that CRUD SQL stands for C an we R eally not U se SQL D atabases they may S eem familiar but all the ORM stuff is well over our Q uota for comp L icated dependencies.
In an event driven system applications subscribe to be notified when new events occur. They can create read models as the events arrive. Those read models are what the application uses to, erm, read data. So they're used in places many applications make SQL queries. Now this visit plannr application needs a read model for recently updated destinations.
What even is a Read Model?
The query (or read) model is a denormalized data model. It is not meant to deliver the domain behaviour, only data for display (and possibly reporting).
CQRS-based views can be both cheap and disposable … any single view could be rewritten from scratch in isolation or the entire query model be switched to completely different persistence technology
- both from Page 141 Implementing Domain Driven Design by Vaughn Vernon
A CQRS system (see part 1) separates the parts of the application(s) that receives commands to change from those that receive queries for data. Read models are the data models for the read side of the application. This lets you optimise different areas for their specific tasks.
Read models are a representation of the data built for a particular query. You can reuse read models. However in a CQRS or eventsourced system you tend to make many read models.
If Sam and Jamie both come to my house to help me garden my eventstream would be:
[
{name: "Sam", type: "CameToGarden"},
{name: "Jamie", type: "CameToGarden"}
]
I can build two readmodels from this:
{helperCount: 2}
{peopleHelping: ["Sam", "Jamie"]}
So each read model in a system is a different way of representing written data in order to serve a particular need. Think of them as different SQL projections or views over tables. They aren't the data they're something built from the data that lets you show it to someone.
A wonderful thing about read models (in an eventsourced system at least) is that you can throw them away. Imagine a SQL database that you can delete once you don't like its shape. In a system with read models you can change your code, reset the system that builds the read model to start at the beginning of history, and let it create the new read model.
Work an example
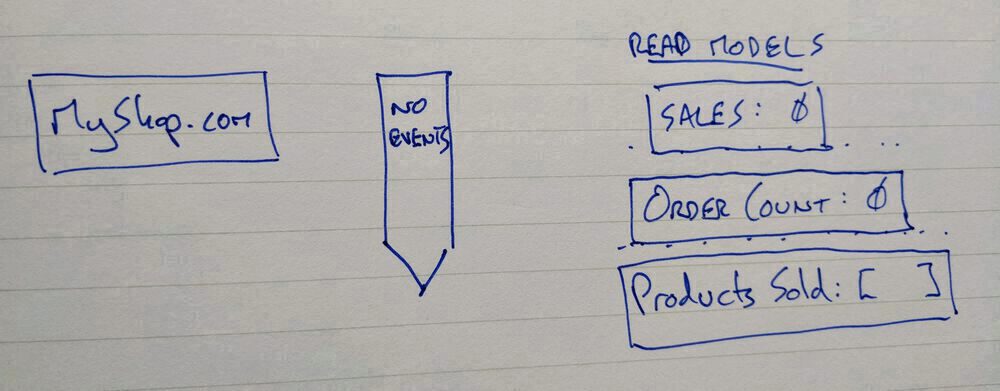
Let's imagine an eventsourced ecommerce application with no events. Sales and fulfilment teams need to know how much money we've made, how many orders we've taken, and what products have been sold.
We've deployed 3 separate applications that are subscribed to the empty event stream.
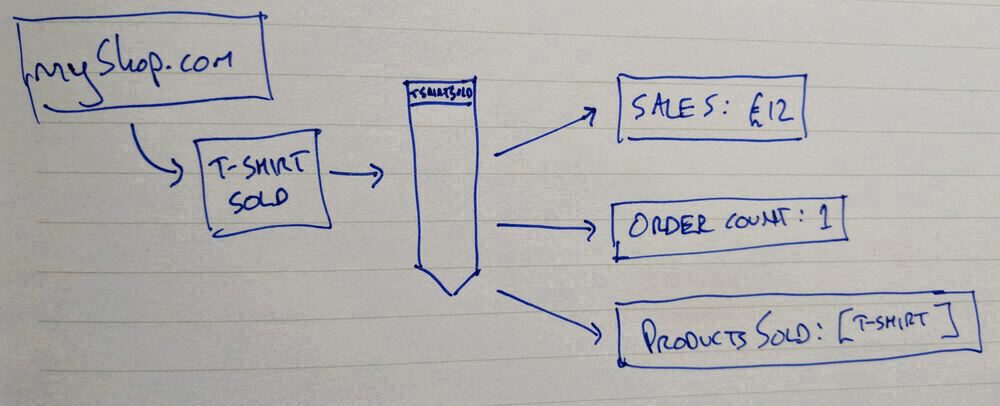
Big day - the first sale! myshop.com writes an event to the stream that we've sold a t-shirt. The sales, order count, and products sold read models update and any UI or report being generated using them can update accordingly.
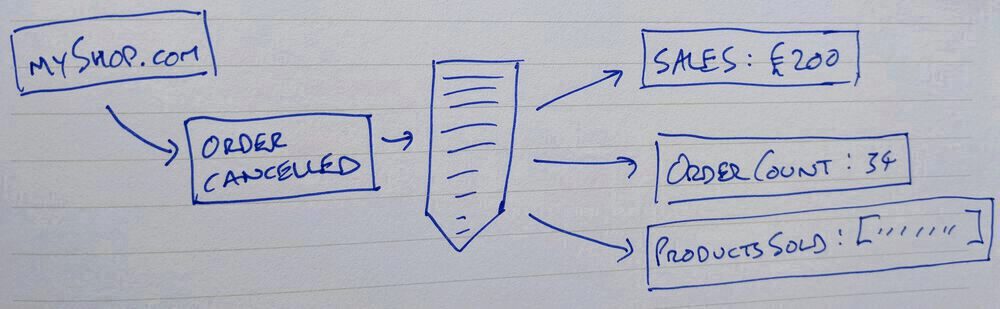
Many days and events have passed and after the most recent cancelled order the fulfilment team let you know that it's really hard for them to figure out what's happening when an order is cancelled. They'd like a view to help them manage cancellations.
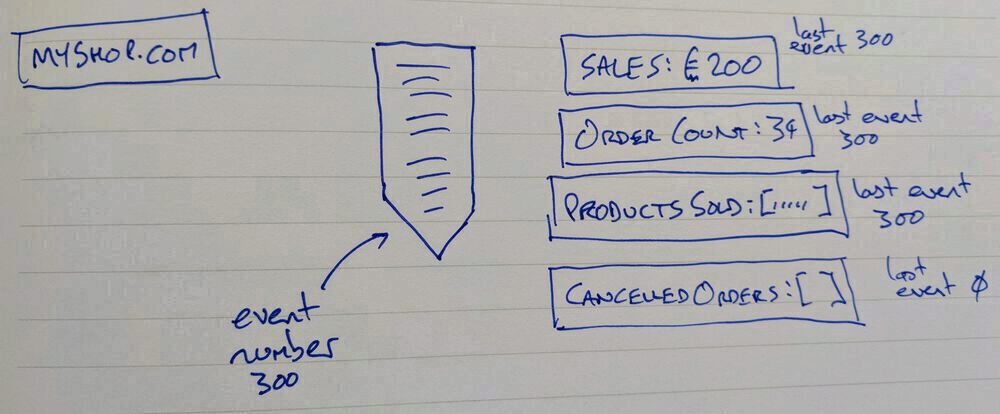
So a new read model is built and deployed to track order cancellations. The existing read models are all up-to-date on event 300. When the new application starts its read model isn't showing any cancelled orders and it has read 0 events.
(important to note that no other applications had to change at all to support this!)
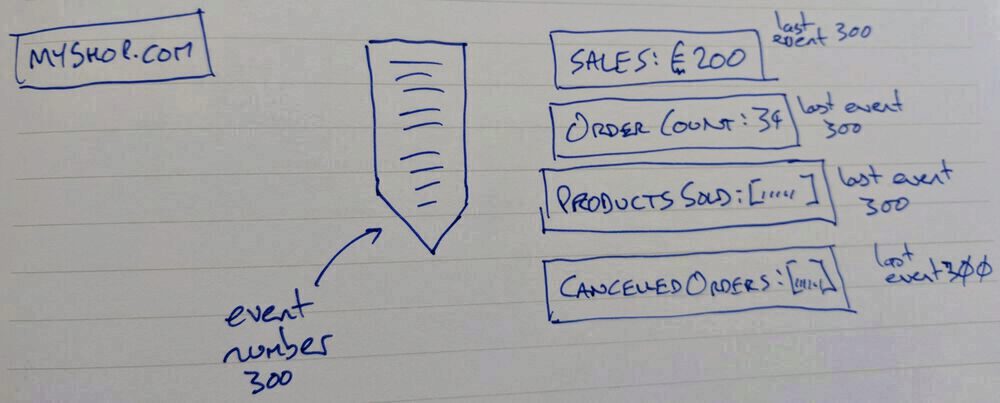
The new application reads through the event stream until it has caught up. There's a period of time where it is reading through the event stream and performing any calculations or running any logic where it isn't caught up with the other read models or with the write side of the applications.
This is 'eventual consistency'. An event sourced system embraces the benefits of not trying to force all the parts of the application to stay exactly in sync with each other all the time.
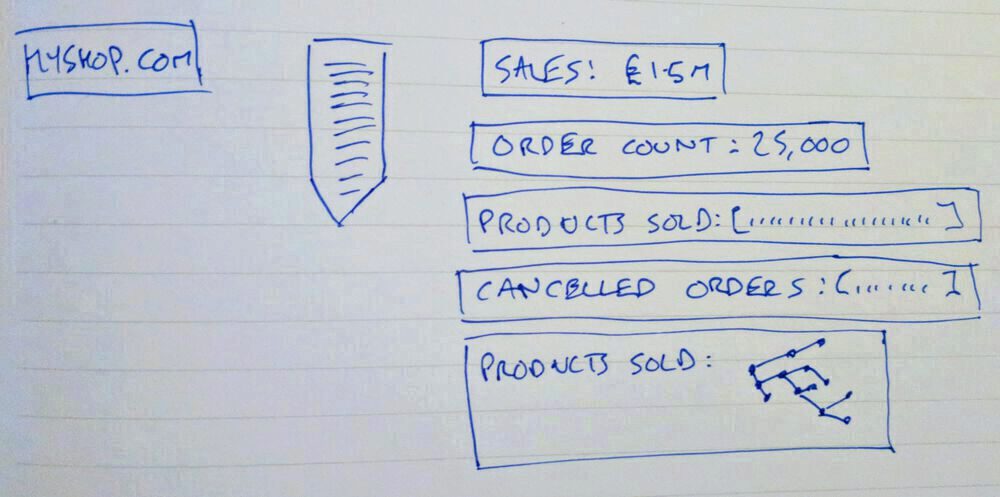
As the website gets more popular storing the products sold in an array is limiting what business intelligence the sales team can gather. You can add a consumer that stores products sold in a graph database.
As your new data science capability learns what structure they want in this new data store it is possible to keep deleting the graph store and letting it recreate from the event stream. Again this is an addition that doesn't need changes to the existing applications.
Why a Read Model now?
The system has a command channel to propose destinations, and an event subscriber that validates the proposed destination. Now a new event subscriber can respond to each event in a destination stream and create or update a read model used to let people view the destinations on the website.
How to make a read model in this system?
If this system was a long running process it would start, read all the events from the beginning of time (or the last snapshot), build a read model in-memory, and start serving requests once the read model was up-to-date with the event stream.
It also subscribes to the event stream so each subsequent event written to the stream is applied to the read model store. Even with millions of events in a stream once the system has caught up it is only applying one event at a time. Only applying one event can be incredibly fast!
And as in the graph database example above read models don't have to be in-memory. They can be pretty much anywhere. You can run graph databases, document databases, sql databases, and flat files side-by-side as read models for different uses.
Serverless systems only run for the lifetime of each request and so need to start as fast as possible. Building the read model from scratch on-start can be treated as too slow and we'll decide to store the read model in dynamodb.
The lambda
This is kept as a port into the system
exports.handler = async (event) => {
streamReader =
streamReader ||
makeStreamRepository.for(
eventsTableName,
dynamoDbClient.documentClient(),
guid
);
readModelWriter =
readModelWriter ||
makeReadModelRepository.for(
readModelsTableName,
dynamoDbClient.documentClient(),
guid
);
const writes = await readModelUpdateHandler
.withStreamReader(streamReader)
.withReadModelWriter(readModelWriter)
.allowingModelsWithStatus(terminalEventType)
.writeModelsFor(event);
return Promise.all(writes);
};
It initialises a stream reader and a model writer then curries a handler function which receives the event that triggered the lambda. Accepting a terminalEventType so destinations that shouldn't be shown to users yet can be filtered out. Finally waiting for any dynamodb writes to be gathered and passes those promises back to the executing environment so it can wait for them to complete.
The handler is small.
const destinationReadModel = require("./destinationReadModel.js");
const streamNames = require("./streamNames");
module.exports = {
withStreamReader: (streamReader) => ({
withReadModelWriter: (modelWriter) => ({
allowingModelsWithStatus: (status) => ({
writeModelsFor: async (event) => {
console.log(`processing trigger event: ${JSON.stringify(event)}`);
const readPromises = streamNames
.from(event.Records)
.map((cs) => streamReader.readStream({ streamName: cs }));
const streamsOfEvents = await Promise.all(readPromises);
const writes = streamsOfEvents
.map((streamOfWrappedEvents) =>
streamOfWrappedEvents.map((x) => x.event)
)
.map(destinationReadModel.apply)
.filter((m) => m.status === status)
.map(modelWriter.write);
return writes;
},
}),
}),
}),
};
The triggering event could contain more than one dyanamodb update so:
const readPromises = streamNames
.from(event.Records)
.map((cs) => streamReader.readStream({ streamName: cs }));
const streamsOfEvents = await Promise.all(readPromises);
Remember each event is appended onto the end of a stream of events that represents an instance of a particular domain concept. So each destination has its own stream of events that make up the history of that destination. This code reads the stream name from each of the events that triggered the lambda and reads all of the events from each of those streams from dynamodb.
const writes = streamsOfEvents
.map((streamOfWrappedEvents) => streamOfWrappedEvents.map((x) => x.event))
.map(destinationReadModel.apply)
.filter((m) => m.status === status)
.map(modelWriter.write);
each stream of events is applied to a destinationReadModel which are filtered to keep only those with the desired status. Those models are then written to dynamodb so other applications can query them.
module.exports = {
apply: (events) => {
const readModel = events.reduce(
(model, event) => {
switch (event.type) {
case "destinationProposed":
model.name = event.name;
model.geolocation = event.geolocation;
model.timestamp = event.timestamp;
break;
case "geolocationValidationSucceeded":
model.status = "locationValidated";
break;
case "geolocationValidationFailed":
model.status = "failed";
break;
}
return model;
},
{ status: "pending", type: "destination" }
);
console.log(
`built readmodel ${JSON.stringify(
readModel
)} from events ${JSON.stringify(events)}`
);
return readModel;
},
};
Building the read model involves taking each event and updating a model based on the event type. Here you can see how this code is tolerant of events it isn't expecting - it will ignore them.
There's no validation that the data being read from the events is present. Whether there should be validation at this stage is context dependent. Here we wrote the event producers and know that for there to be a geolocationValidationSucceeded event both name and geolocation have to be present. We can trust that the read model will be good enough for now.
What's next?
Now that read models are being stored in dynamodb the next step is to generate a home page. Because the read models are writing to a dynamodb table they can be treated as a projection (read models that can be treated as an eventstream and subscribed to) and we can generate static HTML when the read models change.
All the code for this post can be found here on github.