
After describing event-driven and serverless systems in part one it is time to write some code. Well, almost. The first task is a walking skeleton: some code that runs on production infrastructure to prove we could have a CI pipeline.
I think I'll roll my AWS credentials pretty frequently now - since I can't imagine I'll get through this series without leaking my keys somehow
¯\_(ツ)_/¯
Putting authentication and authorisation to one side, because the chunk is too big otherwise, this task is to write a command channel to allow editors to propose destinations on the visitplannr system.
This requires the set up of API Gateway, AWS Lambda, and DynamoDB infrastructure and showing some code running. But doesn't require DynamoDB table streams or more than one lambda.
That feels like a meaningful slice.
The moving pieces
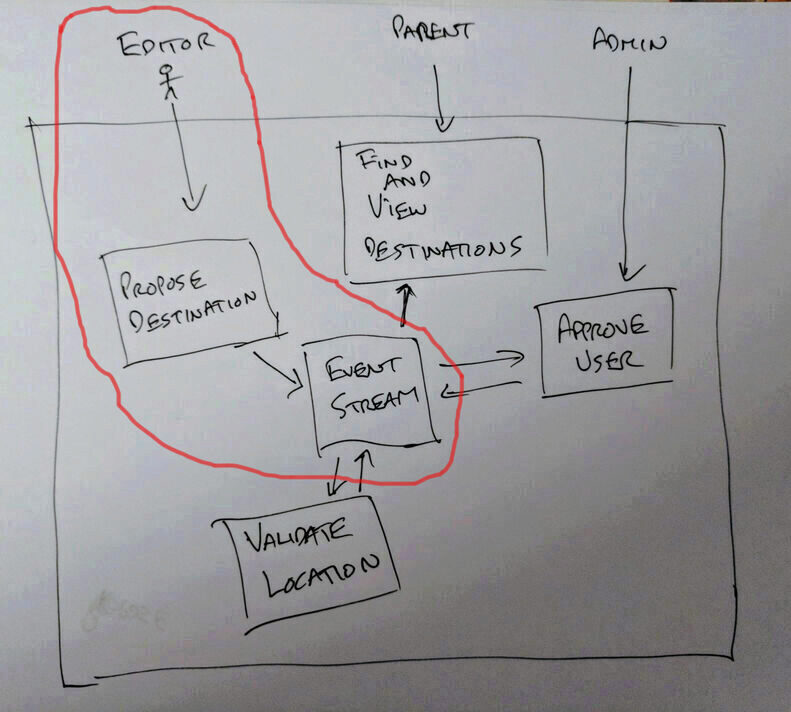
Infrastructure as Code
We use terraform at work so it would be quite productive to use that - but I wanted to try out SAM local to understand its local development story and deployment using CloudFormation.
From the docs: "SAM Local can be used to test functions locally, start a local API Gateway from a SAM template, validate a SAM template, and generate sample payloads for various event sources."
The Serverless Application Model or SAM is based on CloudFormation. With the aim of defining "a standard application model for serverless applications".
CloudFormation is an AWS specific infrastructure as code resource letting you author entire application stacks as JSON or YAML. That let's you launch "application stacks", in this case: API Gateway, Lambda, and DynamoDB.
Code as Code
AWS lambda now runs many awesome languages (NodeJS, Python, C#, Java, and Go). I 💖 JavaScript and have already experimented a few times over the last few years with NodeJS in Lambda. So will write the application in Node.
There are a number of frameworks that sit on top of AWS Lambda and API Gateway. Such as Claudia.js or Serverless. But I didn't want any of the details hidden away from me so haven't investigated them at all (which may be cutting off my arm to spite my face).
The eventstream
It is common to use dynamodb as the storage mechanism for Lambda. "Amazon DynamoDB is highly available, with automatic and synchronous data replication across three facilities in an AWS Region."
Which highlights one of the benefits of the serverless model - geographically distributed HA database by default.
It can read and write JSON, and allows you to subscribe to the stream of changes for a table. So most likely fits the needs of this application.
The SAM template
The SAM template is (once you're used to the syntax) pretty straightforward.
A header describing this template and the versions of the language used:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: |
A location and weather aware day-trip planner for parents
a list of the resources to be created:
Resources:
A dynamodb table definition:
EventsTable:
Type: "AWS::DynamoDB::Table"
Properties:
AttributeDefinitions:
- AttributeName: StreamName
AttributeType: S
- AttributeName: EventId
AttributeType: S
KeySchema:
- AttributeName: StreamName
KeyType: HASH
- AttributeName: EventId
KeyType: RANGE
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
There are two types of primary key in dynamodb. And this is the first design decision which will need validation in future. In fact in a "real" project this would need a lightweight architecture decision record. So let's add one here.
The first kind of primary key in DynamoDB is having only a partition key. The partition key is hashed and determines where on physical storage the item is placed. The partition key must be unique.
The second kind is a composite primary key. It consists of a partition key and a sort key. The partition key no longer needs to be unique in isolation. Rather the sort key/partition key pair must be unique.
In a real system this would probably push towards StreamName as the partition key: so that events that logically live together physically live together. And EventNumber in the stream as the sort key. So that the order of items as they are stored on physical media matches the order they are likely to be read.
This would introduce a bunch of complexity in code for tracking event numbers so for now instead of an EventNumber as the sort key the decision is to introduce a UUID EventId. This will need performance testing to check that there is no significant impact of the items being sorted by UUID.
The "ProvisionedThroughput" setting show where the abstraction starts to leak and the fact that these services run on infrastructure bleeds through. Under the hood AWS is reserving capacity for dynamodb - after all they definitely do have to capacity plan their infrastructure so that we don't have to.
"One read capacity unit = one strongly consistent read per second, or two eventually consistent reads per second, for items up to 4 KB in size.
One write capacity unit = one write per second, for items up to 1 KB in size."
So the system needs to be sized against the expected read and write throughput.
The AWS SDK has retries built in for if the AWS service throttles your reads or writes when you are over capacity. This would be an area that would need testing and monitoring in a real system.
It's important to note that the "cost" of managing that capacity setting is probably lower than the cost of creating, managing, and maintaining your own distributed, highly-available, (potentially) multi-master database cluster.
And worth saying that on Prime Day 2017 Amazon's own use of DynamoDB peaked at nearly 13 million reads per second. So the need for throughput limits in config isn't because the service can't cope with your load.
The lambda and API gateway definition:
ProposeDestinationFunction:
Type: AWS::Serverless::Function
Properties:
Runtime: nodejs6.10
Handler: proposeDestination.handler
Timeout: 10
Policies: AmazonDynamoDBFullAccess
Environment:
Variables:
EVENTS_TABLE: !Ref EventsTable
Events:
ProposeDestination:
Type: Api
Properties:
Path: /destination
Method: POST
This sets a lambda function with a given handler, and runtime. The handler is the code that will run when the event is received. And sets an environment variable to reference the created dynamodb table.
Finally sets that this lambda function will be triggered by an API POST to /destination. Which is all SAM needs in order to create an API gateway to trigger the lambda.
With 39 lines of YAML SAM will provision an API gateway, a lambda function, and a dynamodb function. All highly available, elastic, and distributed geographically - that's pretty funky!
The handler code
exports.handler = (event, context, callback) => {
console.log(`received event: ${JSON.stringify(event)}`);
callback(null, {
statusCode: 200,
body: "OK",
});
};
First things first:
- No semi-colons. Live with it. It's great.
- standardjs - I don't agree with all of standardjs' decisions but I do recognise that since they're largely arbitrary I shouldn't care.
This is a lambda function. It's about as small a function as you can write to respond to an event from API gateway. First it logs the received event. Then it tells API gateway to return a http status 200 with the body 'OK' to the client.
Anchors away!
After incurring the incredible cost of $0.02 because I kept forgetting to strip chai and mocha from the bundle I wrote a deployment script.
#! /bin/bash
set -eux
rm -rf node_modules/
npm install --only=production
if aws s3 ls "s3://visitplannr" 2>&1 | grep -q 'NoSuchBucket'
then
aws s3 mb s3://visitplannr
fi
sam package --template-file template.yaml \
--s3-bucket visitplannr \
--output-template-file packaged.yaml
sam deploy --template-file ./packaged.yaml \
--stack-name visitplannr \
--capabilities CAPABILITY_IAM
- remove node_modules directory
- npm install all of the non-dev dependencies (there aren't actually any yet!)
- make sure there's an s3 bucket to upload the code into
- run
sam packagewhich translates to CloudFormation and uploads the code to s3 - run
sam deploywhich launches the application stack
Running that creates everything necessary in AWS. Looking at the created stack there are more pieces created than needed to be specified.
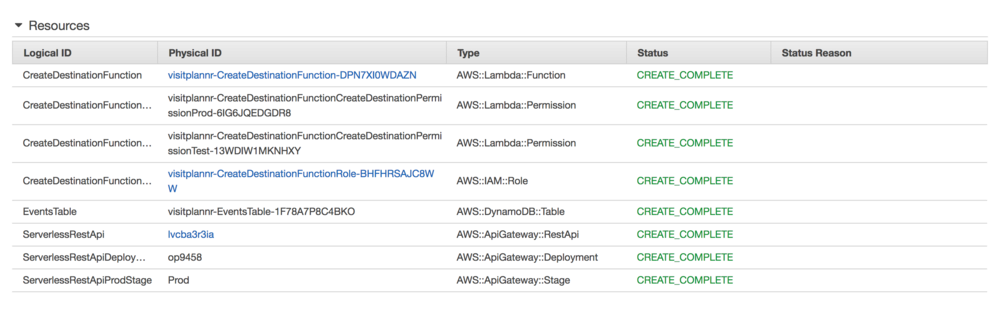
This includes the IAM roles to allow these resources to talk to each other. These at least in part result from the config line: Policies: AmazonDynamoDBFullAccess applied to the lambda function.
This is much more access than we need. But in the interest of not getting diverted the necessity for finer grained access goes on the to-do list - it's possible but not necessary right now.
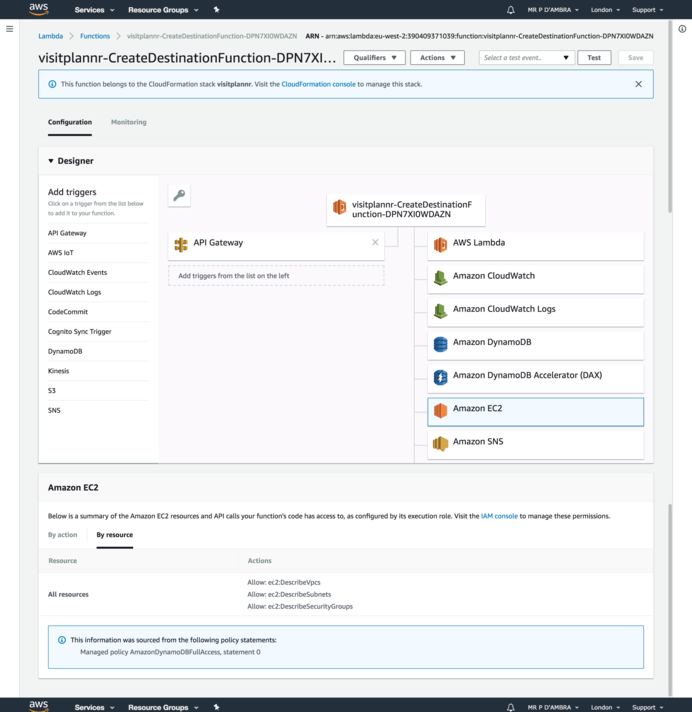
The wider than necessary access can be seen in the lambda console which lists out the resources the function can access and the policy that makes that access possible.
The API Gateway console shows the new endpoint
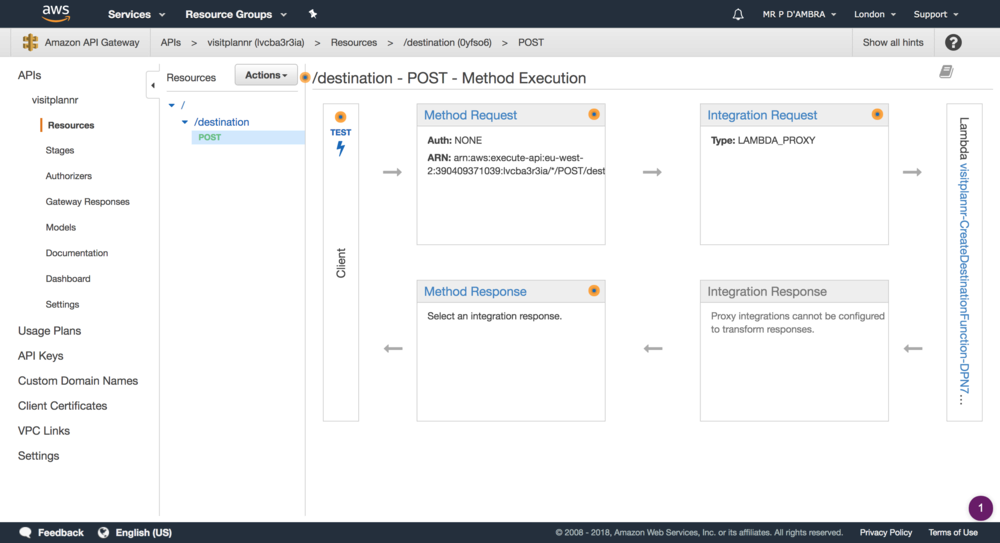
The endpoint can be tested right in the console:
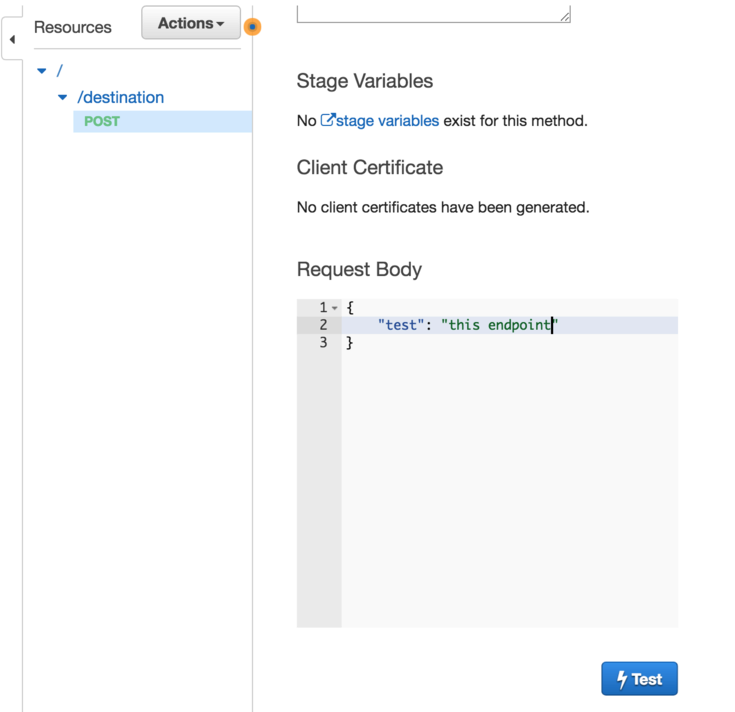
and the results are logged in the page
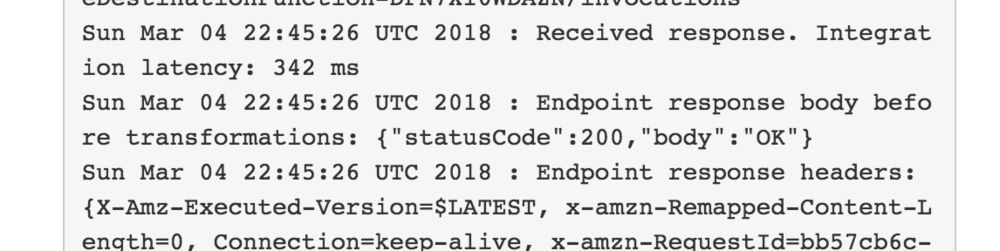
And finally, the cloudwatch logs show the output from running the lambda.
That
console.log(`received event: ${JSON.stringify(event)}`);
results in logging:
2018-03-04T22:45:26.854Z bb57cb6c-1ffd-11e8-b4a3-d7ae7c406190 received event:
{
"resource": "/destination",
"path": "/destination",
"httpMethod": "POST",
"headers": null,
"queryStringParameters": null,
"pathParameters": null,
"stageVariables": null,
"requestContext": {
"path": "/destination",
"accountId": "123456",
"resourceId": "0yfso6",
"stage": "test-invoke-stage",
"requestId": "test-invoke-request",
"identity": {
"apiKeyId": "test-invoke-api-key-id",
"userAgent": "Apache-HttpClient/4.5.x (Java/1.8.0_144)",
"snip": "much more info"
},
"resourcePath": "/destination",
"httpMethod": "POST",
"apiId": "lvcba3r3ia"
},
"body": "{\n \"test\": \"this endpoint\"\n}",
"isBase64Encoded": false
}
and each invocation also logs a line like:
REPORT RequestId: bb57cb6c-1ffd-11e8-b4a3-d7ae7c406190 Duration: 15.92 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 20 MB
Showing you the actual and billed durations and the used memory compared to the provisioned memory.
More leaky abstractions
So, it isn't that you don't have to care at all that there are servers. AWS Lambda charges per 100ms of function invocation. The amount of time you get for free and the cost per 100ms varies depending on how much RAM you allocate to the function.
In fact, increasing the RAM actually increases the underlying compute, network, threads, and more. In some experiments at Co-op Digital we saw that scaling for a network and compute bound workload was pretty important.
DynamoDB
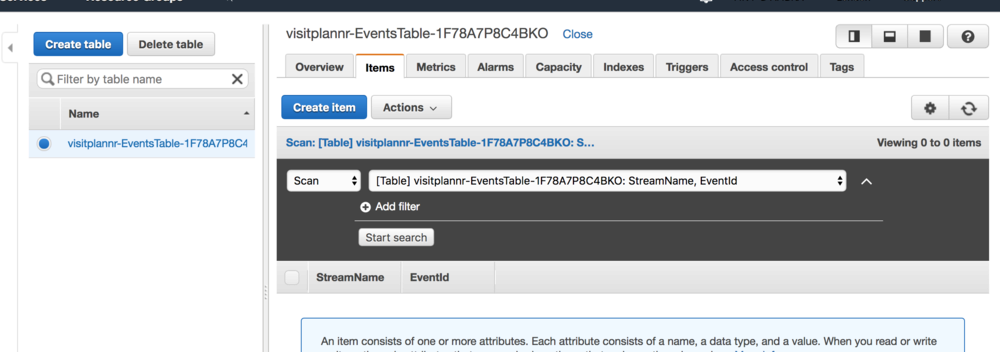
The table has been created and is ready to be used. The config we've used doesn't actually setup the table for autoscaling. But we'll loop back around and tidy that up later. It's another detail that doesn't need nailing right now.
Let's review
With 39 lines of YAML we've created a walking skeleton to prove we can write code locally and deploy it to AWS.
We've had to learn a little about the details of dynamodb and AWS lambda where they leak their underlying infrastructure into our worlds - although presumably there's a setting equivalent to "I care less about how much I spend than how much resource you use - charge me what you like and don't bother me again". I don't want to turn that on (yet).
All the code for this stage can be found on github
And we're finally ready to write some tests. In the next post we'll look at some tests, talk about the final state of the handler, and look at how to set up locally to run integration tests.
And delete
aws cloudformation delete-stack --stack-name visitplannr && aws s3 rb s3://visitplannr --force
This tells AWS to delete everything since I don't want to pay money for an application stack that nobody is using and only exists for my (unashamedly very low readership) blog.