Serverless - Part Six - Making a view
Part One - describing event-driven and serverless systems
Part Two - Infrastructure as code walking skeleton
Part Three - SAM Local and the first event producer
Part Four - Making streams of events
Part Five - Making a read model
In part 5 the code was written to make sure that whenever a destination changes the recent destinations read model will update. Now that read model can be used to realise a view that a human can use. We'll add code to create a HTML view behind AWS cloudfront. This will demonstrate how event driven systems can be created by adding new code instead of changing existing code.

Serverless - Part Five - Read Models
Part One - describing event-driven and serverless systems
Part Two - Infrastructure as code walking skeleton
Part Three - SAM Local and the first event producer
Part Four - Making streams of events
OK, four months since part four. I got a puppy and have written the code for this part of the series in 2 minute blocks after sleepless nights. Not a productive way to do things!
Getting ready to make some HTML
Now that the API lets clients propose destinations to the visit plannr the home page for the service can be built. It's going to show the most recently updated destinations.
In a CRUD SQL system the application would have been maintaining the most up-to-date state of each destination in SQL and you'd read them when the HTML is requested. But this application isn't storing the state of the destinations but the facts that it has been told about the destinations.
As an aside a lot of people don't realise that CRUD SQL stands for C an we R eally not U se SQL D atabases they may S eem familiar but all the ORM stuff is well over our Q uota for comp L icated dependencies.
In an event driven system applications subscribe to be notified when new events occur. They can create read models as the events arrive. Those read models are what the application uses to, erm, read data. So they're used in places many applications make SQL queries. Now this visit plannr application needs a read model for recently updated destinations.
DRY - considered harmful
DRY or WET?
DRY, in software development, stands for Don't Repeat Yourself. This is often taken to mean remove any duplication of lines of code. See the anti-example in the wiki page comparing to WET code - which stands for Write Everything Twice. This reinforces the idea that this is about the amount you type.
Below we're going to look at what the impact of removing duplication of lines of code does to some software, hopefully demonstrate that it isn't desirable as an absolute rule, and show what the better way might be.
Serverless - Part Four
Part One - describing event-driven and serverless systems
Part Two - Infrastructure as code walking skeleton
Part Three - SAM Local and the first event producer
In this post we start to see how we can build a stream of events that lets us create state. We'll do this by adding an event subscrber that waits until a user proposes a destination to visit and validates the location they've provided.
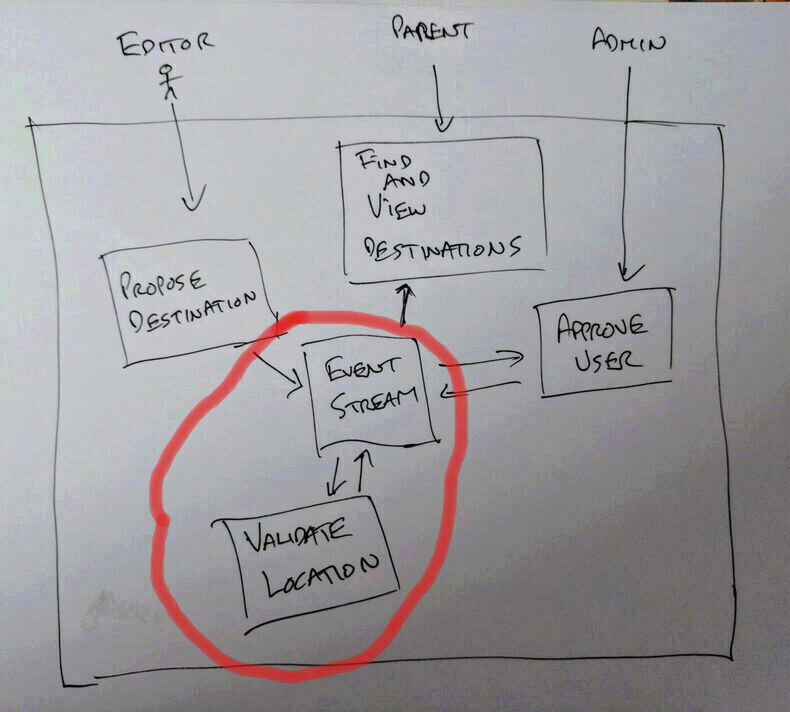
Serverless - Part Three
Part One - describing event-driven and serverless systems
Part Two - Infrastructure as code walking skeleton
In this post we will look at how SAM local let's you develop locally and write the first lambda function. To take a ProposeDestination command and write a DestinationProposed event to the eventstream.
"SAM Local can be used to test functions locally, start a local API Gateway from a SAM template, validate a SAM template, and generate sample payloads for various event sources."
Serverless - Part Two
After describing event-driven and serverless systems in part one it is time to write some code. Well, almost. The first task is a walking skeleton: some code that runs on production infrastructure to prove we could have a CI pipeline.
I think I'll roll my AWS credentials pretty frequently now - since I can't imagine I'll get through this series without leaking my keys somehow
¯\_(ツ)_/¯
Putting authentication and authorisation to one side, because the chunk is too big otherwise, this task is to write a command channel to allow editors to propose destinations on the visitplannr system.
This requires the set up of API Gateway, AWS Lambda, and DynamoDB infrastructure and showing some code running. But doesn't require DynamoDB table streams or more than one lambda.
That feels like a meaningful slice.
Serverless - Part One
Anyone who knows me knows that I like to talk about Event-driven systems. And that I'm very excited about serverless systems in utility computing.
I started my career in I.T. having to order network cables, care about fuses, and plan storage and compute capacity. It was slow, frustrating, and if you got it wrong it could take (best case scenario!) days to correct.
Over a few articles I hope to communicate what serverless is, why you should find it exciting, and how to start using it.
Let's start by defining our terms…
Is where we're going where we're going
Velocity is…
A way of measuring the progress being made by a software team. Not all teams use velocity. I've been on quite a few that do. So at least some teams still use it as a measure.
Constructiphor
On Twitter I…
…made a toot-storm about using construction as a metaphor for software engineering.
I've never really got on with construction metaphors for software. The cost of mistakes and rework is high in construction

This isn't saying that Software isn't putting things together but rather I've seen people justify not 'being agile' by using construction metaphors.
Testing Meaning in HTML!
One of the benefits of generating a site as a static artefact (here using Jekyll but there are a gazillion tools) is that the finished product is a known quantity. Anything that's a known quantity can be tested!
A previous post in this series looked at testing the generated HTML for technical correctness… Things like if the HTML is well-formed or that links go to real destinations.
This post describes testing the meaning of the text in the generated HTML. Checking spelling, and keeping myself honest in my attempt to use more inclusive language.